Writing Modern PyTorch
my thoughts on some popular PyTorch libraries and good coding practices



- PyTorch
- Lightning
- Writing Modern Python
- Einops: Einstein Operations on Tensors
- Using nn.Sequential()
- Kornia
PyTorch
![]()
Learning a programming language/framework is a lot like learning foreign languages. Just studying them online or from a book is hardly sufficient and one needs to get actively involved in conversations and discussions to get the pronunciation and flow of speaking right. The same goes for writing code, so get started on the PyTorch Forums and Stack Overflow.
I'm writing this post after 2 years of using PyTorch, after having started learning from Udacity courses and online blogs, to heavily experimenting with PyTorch's functionalities during my bachelor's thesis, and then more recently having finished the fast.ai's Deep Learning from Foundations where Jeremy Howard recreates several core modules of PyTorch and discusses his thought process on creating the latest fastai library.
The purpose of this post is to not to be an all-purpose tutorial or template since there're already a lot of amazing people out there teaching PyTorch, but instead it aims to answer the FAQs and guide people to the right resources.
Getting Started

If I had to start learning PyTorch all over again, I wouldn't think twice and dig deep into everything Jeremy Howard has to offer. He is the co-founder of fast.ai along with Rachel Thomas and every year they release several courses on deep learning for free. This is world-class educational content you can enjoy at no cost, not even any ads or sponsors * gasps *. There aren't many quality things in the world that come for free so I would definitely recommend you to check fast.ai out.
If you're confused where to start from all the courses offered, I would suggest watching the first 2-3 videos of their most recent offering of "Practical Deep Learning for Coders", and in parallel starting with the course Deep Learning from Foundations
If you're looking for a fast-track introduction to PyTorch, you can read this tutorial "What is torch.nn really?" by Jeremy on the official PyTorch page.
Educational vs Practical
At this point, I must also point out that I have sort of a love-hate relationship with fastai owing to some aspects of their coding style. Even though I've been bluntly advertising them since the start of this post, I do not use the fastai library so often for my projects. I think fastai is the best educational library out there which will get you SOTA results for tasks like Image Classification, Segmentation and a bunch of other tasks in less than 10 line of code, but the fact that instead of developing their library around existing PyTorch functionalities and supporting them, they have tried to create their own abstractions by rewriting PyTorch modules like DataLoaders and introduced their own optimizers, without providing enough extra utility to balance the trade-off.
What I do use regularly from fastai is a tonne of ideas that I learned while doing their courses like proper weight initialization, learning rate finder, OneCycle training policy, callbacks, PyTorch Hooks and visualizing layer histograms, just to name a few.
PyTorch vs Keras/TF
Sometimes you would see people fighting over PyTorch vs Keras/Tensorflow and which is better. I usually don't enjoy such debates, or even support PyTorch for that matter. I believe there's a variety of people out there who have their own programming style preferences, and whichever framework suits their taste better, they should use it. I feel more comfortable and cognitively at ease using PyTorch and that's why I prefer the PyTorch ecosystem, but at the same time I don't mind working with Tensorflow whenever I have to.

I do like PyTorch vs TF memes though, who doesn't?

Lightning

From "vanilla" PyTorch, I have recently shifted to PyTorch Lightning, which is another great library started by William Falcon, which I quote from their docs "doesn’t want to add any abstractions on top of pure PyTorch. This gives researchers all the control they need without having to learn yet another framework." It helps you reorganize your PyTorch code while providing multi-GPU and half-precision training, extensive callback system, inbuilt Tensorboard logging and a lot more on the go.
Convert your PyTorch code to Lighting in 3 steps as shown here. They also have an active Youtube Channel which shows how to convert your existing PyTorch code to Lightning, and also cover implementation of new papers in self-supervised learning.

Writing Modern Python
You should go through this excellent post on Python3 features by Alex Rogozhnikov where he discusses type hinting, better globbing, f-strings, data classes, using Enum for constants, and a lot more. He is also the creator of einops, the library we'll discuss next
Einops: Einstein Operations on Tensors
Einops is one of my favorite libraries, one that gives me ASMR and one that I wish I had known while starting with PyTorch. It's written by Alex Rogozhnikov and works with all major deep learning libraries. The tutorial for using it with PyTorch: Writing a better code with pytorch and einops.
The original post is a delight to read so I'm going to post only one example from that and not much.
your code becomes much cleaner and understandable when using nn.Sequential(). You would have already realized it by now if you read the post linked above.
class SuperResolutionNetOld(nn.Module):
def __init__(self, upscale_factor):
super(SuperResolutionNetOld, self).__init__()
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
self.conv2 = nn.Conv2d(64, 64, (3, 3), (1, 1), (1, 1))
self.conv3 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
self.conv4 = nn.Conv2d(32, upscale_factor ** 2, (3, 3), (1, 1), (1, 1))
self.pixel_shuffle = nn.PixelShuffle(upscale_factor)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
x = self.pixel_shuffle(self.conv4(x))
return x
A better implementation would be
from einops.layers.torch import Rearrange
def SuperResolutionNetNew(upscale_factor):
return nn.Sequential(
nn.Conv2d(1, 64, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 32, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(32, upscale_factor ** 2, kernel_size=3, padding=1),
Rearrange('b (h2 w2) h w -> b (h h2) (w w2)', h2=upscale_factor, w2=upscale_factor))
class Binarizer(torch.autograd.Function):
"""
An elementwise function that bins values
to 0 or 1 depending on a threshold of 0.5,
but in backward pass acts as an identity layer.
Such layers are also known as
straight-through gradient estimators
Input: a tensor with values in range (0,1)
Returns: a tensor with binary values: 0 or 1
based on a threshold of 0.5
Equation(1) in paper
"""
@staticmethod
def forward(ctx, i):
return (i>0.5).float()
@staticmethod
def backward(ctx, grad_output):
return grad_output
def bin_values(x):
return Binarizer.apply(x)
Creating a Lambda class that acts as a wrapper
class Lambda(nn.Module):
"""
Input: A Function
Returns : A Module that can be used
inside nn.Sequential
"""
def __init__(self, func):
super().__init__()
self.func = func
def forward(self, x): return self.func(x)
def NewEncoder():
return nn.Sequential(nn.Conv2d(3, 128, 8, 4, 2), nn.ReLU(),
nn.Conv2d(128, 256, 4, 2, 1), nn.ReLU(),
nn.Conv2d(256, 64, 3, 1, 1), nn.Sigmoid(),
# Focus here
Lambda(bin_values))
A more naive implementation would've looked something like the one below, and that is without proper initialization.
class OldEncoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
#Encoder layers
self.conv1 = nn.Conv2d(in_channels=3,out_channels=128,kernel_size=8,stride = 4,padding = 2)
self.conv2 = nn.Conv2d(in_channels=128,out_channels=256,kernel_size=4,stride = 2,padding = 1)
self.conv3 = nn.Conv2d(in_channels=256,out_channels=64,kernel_size=3,stride = 1,padding = 1)
def forward(self,x):
x = F.relu(self.conv1(x))#first conv layer
x = F.relu(self.conv2(x))#second conv layer
x = torch.sigmoid(self.conv3(x))#third convolutional layer
x = Binarizer.apply(x)
return x
There are several ways to initialize neural networks and you can read more about them in my post on weight initialization here
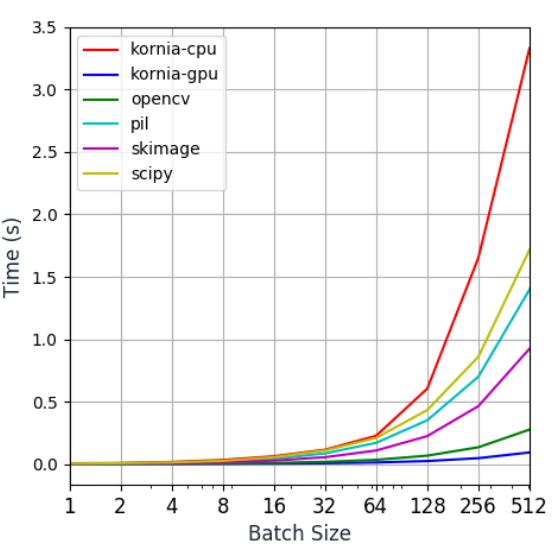
Kornia
Data Augmentation
Data Augmentation in PyTorch pipelines is usually done using torchvision.transforms. The pipeline can be summarized as
Image --> Crop/Resize --> ToTensor --> Normalize
All the augmentattions are performed on the CPU so you need to make sure that your data processing does not become your training bottleneck when using large batchsizes. This is the time for introducing -
![]()
Kornia is a differentiable computer vision library for PyTorch started by Edgar Riba and Dmytro Mishkin, that operates directly on tensors, hence letting you make full use of your GPUs. They have also recently released a paper
It allows you to use data augmentation similar to a nn.Module(), and you can even combine the transforms in a nn.Sequential()
import kornia
transform = nn.Sequential(
kornia.enhance.AdjustBrightness(0.5),
kornia.enhance.AdjustGamma(gamma=2.),
kornia.enhance.AdjustContrast(0.7),
)
images = transform(images)