Handling the Woes of Training
how to find the best learning rate and add OneCycle training to your deep learning model



Who needs to read this post?
This post is useful if you're training deep learning models (eg. ResNets) for tasks like Image Classification, Object Detection, Image Segmentation and many more. You can use the approaches mentioned here for both training from scratch as well as for fine-tuning. This post is meant to answer questions like
- what is the best learning rate for my model?
we'll look at a learning rate finding policy that takes less than a minute to run
- how to train my models much faster and spend less compute time?
the models train faster as this approach allows us to use much higher learning rates for training that would otherwise be unsuitable
- how does it benefit my model?
using higher learning rates help us avoid getting stuck in local minimas
- how can I schedule my learning rate to get the best performance?
we will implement the OneCycle training policy that this post is about
TL;DR Show me the code
These ideas were popularized by the fastai library which is based on PyTorch, but implements them using Callbacks in their custom training script. If you just want to quickly test and add LRFinder and OneCycle learning rate schedule to your training pipeline, you can directly adapt the code below to your script.
LR Range Test
If you're like me, you would just put 3e-4 into an Adam optimizer and let the model train. But in the last few years, a lot has happened that has made it easier to find the optimal learning rate for our model
In 2015, Leslie N. Smith came up with a trial-and-error technique called the LR Range Test. The idea is simple, you just run your model and data for a few iterations, with the learning rate initially starting at a very small value and then increasing linearly/exponentially after each iteration. We assume that the optimal learning rate is bound to lie between these two extremas, usually taken as [1e-7, 10]. You record the loss for each value of learning rate and plot it up. The low initial learning rate allows the network to start converging and as the learning rate is increased it will eventually be too large and the network will diverge.
A plot for LR Range test should consist of all 3 regions, the first is where the learning rate is too small that loss barely decreases, the “just right” region where loss converges quickly, and the last region where learning rate is too big that loss starts to diverge.
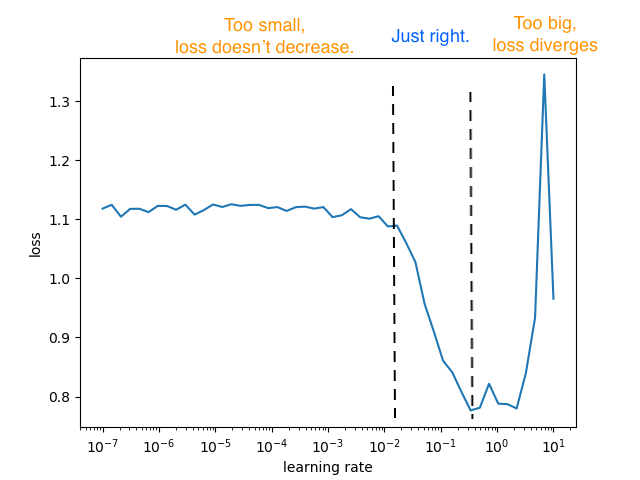
For this test, you can use the library pytorch-lr-finder for finding the best learning rate for your PyTorch model. If you are using PyTorch Lighting, you can use their builtin lr_finder module. A keras implementation is also available here. As you will see later in the post, implementing this finder is pretty straightforward once you understand the method, but I'm linking these libraries here only to give you a headstart.
This is the plot we want to obtain and analyze
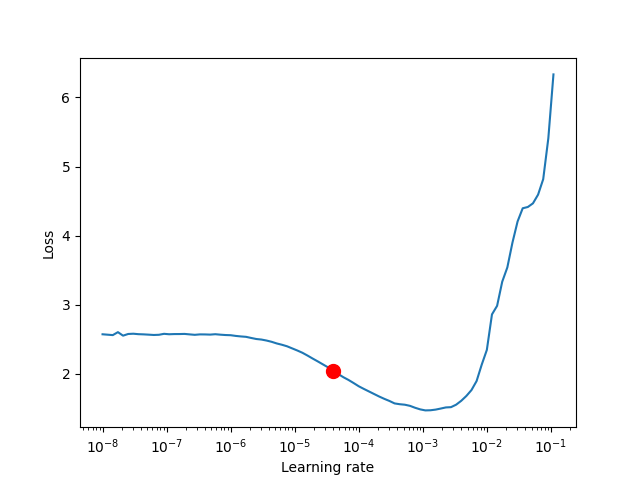
How to Interpret this
It is recommended to not pick the learning rate that achieves the lowest loss, but instead something in the middle of the sharpest downward slope (red point), as this is the point at which loss is still decreasing, whereas at the lowest point, the loss has already started increasing.
OneCycle Training
The OneCyle scheduler is directly available for use in PyTorch. Some things to keep in mind:
-
You have to call
scheduler.step()after every batch. This is unlike most schedulers which are called after every epoch. -
OneCycle works only with optimizers that use momentum (they track the running average of gradients) like SGD, Adam and RMSProp but it won't work with AdaDelta or Adagrad which only track the running average of squared gradients. You'll understand why when we go into details.
-
In my experience, Adam optimizer has worked the best with this schedule.
The idea is to decrease the momentum when increasing the learning rate and to increase it when decreasing the learning rate. With this policy, the author demonstrates an event called “super-convergence”, where it reaches the same validation accuracy in only 1/5 of the iterations.
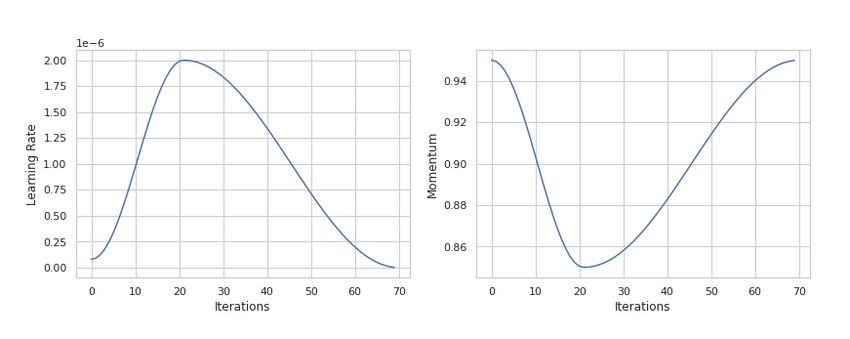
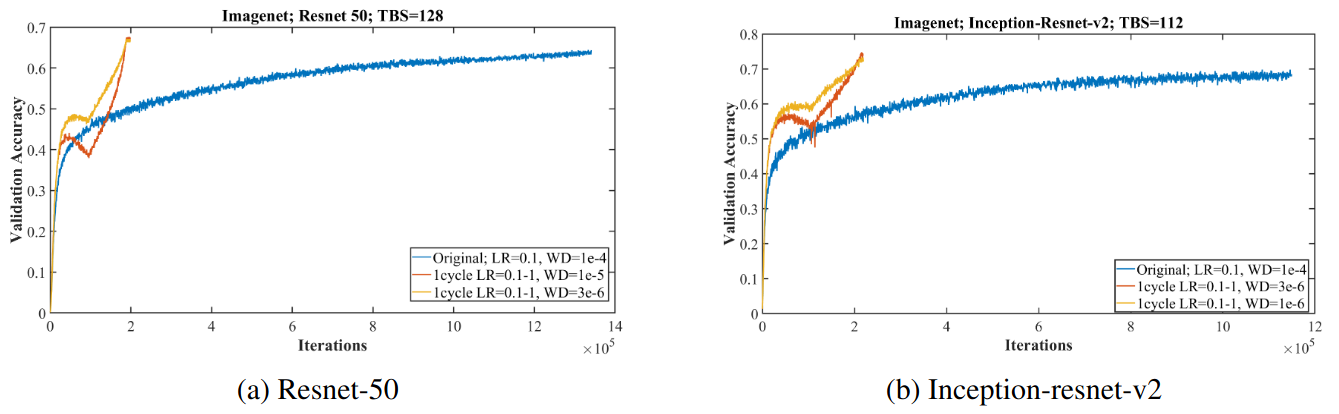
Let's get down to code
def get_lr(optimizer):
""""
for tracking how your learning rate is changing throughout training
"""
for param_group in optimizer.param_groups:
return param_group['lr']
def fit_one_cycle(epochs, max_lr, model, train_loader, val_loader):
history = []
# Set up optimizer
optimizer = torch.optim.SGD(model.parameters(), max_lr)
# Set up one-cycle learning rate scheduler
sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs = epochs,
steps_per_epoch = len(train_loader))
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
lrs = []
for batch in train_loader:
loss = model.training_step(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Record loss
train_losses.append(loss)
# Record & update learning rate
lrs.append(get_lr(optimizer))
sched.step()
# Validation phase
with torch.no_grad():
model.eval()
result = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
result['lrs'] = lrs
history.append(result)
return history
If you want to see the entire training script in action, you can follow the notebooks presented below
Extra Readings
If you want to get deep (pun intended) into playing around with these concepts I would highly recommend you to watch fast.ai's Deep Learning from the Foundations, spending most of your time reimplementing the notebooks by yourself. Here are some other resources that talk about these ideas